


Si hay muchos términos cuyas definiciones se solapan casi completamente entre sí, evidentemente hay una confusión fundamental. La diferencia entre Data Science (ciencia de datos), Data Mining (minería de datos), Data Analytics (análisis de datos) y Knowledge Discovery (búsqueda de conocimiento) usualmente se asocia al conjunto de herramientas o lenguajes utilizados (¿programamos?, ¿usamos herramientas visuales que facilitan el modelado?, ¿Open-source o software propietario?), los perfiles de los que realizan las tareas (¿vienen de la ciencia dura?, ¿son desarrolladores?, ¿o analistas?) y detalles menores asociados al trabajo a realizar (¿es predictivo o prescriptivo?, ¿utiliza algoritmos de aprendizaje automático?).
Los que hemos estado haciendo estas tareas desde hace algún tiempo consideramos que nada de esto es importante y que inclusive esas diferencias que se plantean no son reales: en un mismo proyecto probablemente se use un poco de todo lo mencionado anteriormente. Y de no hacerlo, no es realmente importante. Por lo que lamentablemente para el lector, no seremos nosotros quienes aclararemos la confusión.
Ahora bien, ¿qué es lo que se busca bajo este paraguas de nombres? Simplemente extraer el conocimiento no explícito de los datos, pudiendo ser esto algo tan sencillo como la correlación entre dos variables o algo más complejo como la predicción de la demanda en tiempo real a lo largo de todas las ciudades y barrios del mundo.
En caso de estar algo mareados, podemos usar el siguiente diagrama para orientar las ideas:
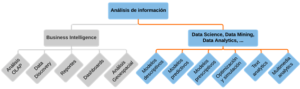
Conceptos básicos
Si bien podemos identificar principalmente dos metodologías para el desarrollo de estas tareas (SEMMA y CRISP-DM, ambas originarias del Data Mining), en la actualidad se tiende a utilizar el siguiente esquema que resume las actividades realizadas en proyectos analíticos.
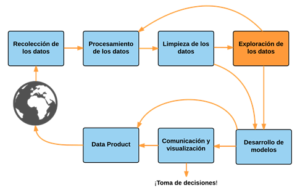
Es importante recalcar que esto no es un reemplazo para las metodologías mencionadas, sino la forma actual de identificar los componentes típicos de un proyecto analítico.
Recolección, procesamiento y limpieza
“El 80% del tiempo uno se la pasa procesando los datos; el 20% entendiéndolos y el resto del tiempo modelando”. Frase célebre, autor desconocido.
El escenario para la recolección y procesamiento de los datos definitivamente cambió a lo largo de estos últimos años. El panorama ahora se completa por al auge y masividad de las redes sociales y la Web 2.0, gracias a las cuales contamos con fuentes adicionales que caracterizan a nuestros clientes ¡y a los de la competencia!
Iniciativas de Open Data, datos públicos y aplicaciones web que cada vez están más orientadas a exponer su información a todo aquel que desee consumirla, nos ayudan a complementar nuestros propios datos con información de contexto. Los flujos de información constantes y en tiempo real, sea de nuestra maquinaria en la planta de producción, del sistema de alarmas, del sistema GPS de nuestra flota, de micro-computadoras usadas para propósitos específicos o aplicaciones como Twitter que constantemente nos está enviando datos, todos nos informarán de lo que está sucediendo en el momento preciso.
Este nuevo panorama estaría incompleto si no mencionáramos la disponibilidad actual de nuevas herramientas y tecnologías que habilitan el procesamiento y análisis de semejantes fuentes. En su conjunto, nos abren un abanico de nuevos análisis posibles. Es lo que hagamos con ellas lo que nos terminará diferenciando de nuestra competencia o señalando el camino hacia nuevas oportunidades. Si queremos considerar a la información como el activo más importante, deberemos arrancar por procesarlo y almacenarlo como tal.
Exploración de datos
El objetivo de esta fase será lograr un entendimiento acabado de los datos, qué representan, cómo lo hacen y todas sus sutilezas.
– ¿Qué representan? Entender el objeto de análisis desde la perspectiva de los datos disponibles.
– ¿Cómo lo hacen? Entender la granularidad de los datos, sus claves y condiciones.
– Sus sutilezas. Identificar y descubrir problemas asociados a la calidad de los datos y su disponibilidad y tomar las decisiones necesarias para superarlos.
Para hacer esto se utilizarán distintas técnicas, siendo las más clásicas el análisis gráfico, el univariado (o estadísticas descriptivas) y el multivariado.
Ya se mencionó la importancia del análisis gráfico en comparación al análisis de métricas descriptivas, por lo que podemos resumir que será a través de esta forma que se podrán extraer fácilmente conclusiones asociadas a la distribución de los datos (“¿los datos tienen sesgo?”), el comportamiento de los valores anómalos (“¿tenemos outliers?, ¿son válidos?, ¿qué hacemos con los valores nulos?”), la estacionalidad de los datos (“¿el fenómeno que estamos analizando tiene fuertes incrementos en momentos concretos del año que se repiten sucesivamente ?”), las tendencias de los valores y más.
Será a través del análisis univariado que nos concentraremos en las variables de manera independiente entre sí, para observar sus características propias. Para hacerlo, utilizaremos principalmente distribuciones de frecuencias, medidas de tendencia central (media, mediana, moda, máximos, mínimos) y medidas de dispersión (varianza, desviación estándar).
Por último, a través del análisis multivariado analizaremos la relación entre dos o más variables. De esta forma buscaremos confirmar relaciones conocidas -validando los datos disponibles- y descubrir nuevas relaciones, en todos los casos cuantificando el grado de esa relación.
Desarrollo de modelos
El desarrollo mismo de los modelos iterará con el procesamiento de los datos y el análisis exploratorio, ajustando y resolviendo temas de datos que vayan descubriéndose a medida que el modelado avanza.
Podemos agrupar los tipos de modelos a construir de la siguiente forma:
Modelos descriptivos
Estos modelos buscan cuantificar las relaciones existentes en un conjunto de datos, idealmente identificando características y comportamientos previamente desconocidos.
Ejemplos de estos modelos pueden considerarse los modelos de clustering y segmentación, donde su busca obtener agrupaciones de datos con características lo más homogéneas posibles dentro de cada grupo y lo más heterogéneas posibles fuera de él. Estos modelos pueden contemplar unas pocas variables (tablas de doble entrada) o ser completamente multivariados (utilizando múltiples variables combinadas entre sí).
Modelos predictivos
El propósito será identificar la probabilidad de ocurrencia de un comportamiento o atributo futuro en base a comportamientos del pasado. Ejemplos de esto son los modelos de predicción del churn (donde se busca identificar aquellos clientes que se darán de baja en el futuro), de predicción de aceptabilidad de una oferta (identificando aquellos clientes más permeables a una acción comercial específica), de credit scoring (donde se trata de predecir aquellos clientes con mayor probabilidad de caer en incumplimiento de pagos) y de detección de fraudes.
Modelos prescriptivos
Nacen como la evolución de los modelos previos, pero aquí no sólo estaremos prediciendo los resultados posibles sino también asociando a cada uno una acción predeterminada. De esta forma, al asociar una acción a cada escenario posible, podremos evaluar las consecuencias de cada uno, prediciendo no sólo los resultados sino sus consecuencias, optimizándolas y sugiriendo cursos de acción. Podría considerarse como un ejemplo de esto un sistema de gestión de acciones comerciales simultáneas, multi-canal y multi-ola. Lo que buscaremos será predecir el mejor resultado, considerando la tasa de aceptación de todas las acciones posibles, tomando en consideración las reglas asociadas a la gestión de cada canal, las preferencias y características de comportamiento de los clientes y su períodos de descanso.
Recomendaciones
Si los datos son el activo más importante de este siglo, es fundamental tratarlos como tal. Dado las actividades relacionadas a Data Analytics son complejas y específicas, donde cualquier error puede tener un impacto directo en el resultado (datos erróneos utilizados para gestionar) o en la escalabilidad de la solución (soluciones de corto plazo que requieren volver a empezar desde cero cada tanto).
Es por eso que es una práctica recomendable utilizar herramientas de propósito específico y complementar el equipo de trabajo existente en una organización con el de especialistas que puedan aportar know-how específico. Este es el caso de Nequi , donde se utilizó tecnología de AWS – Amazon Web Services para desarrollar e implementar soluciones de datos que den soporte a la operación del negocio y a la toma de decisiones.
“Datalytics hace parte activa de nuestro equipo. Es un aliado estratégico en el desarrollo soluciones soportadas en datos, aplicando sus conocimientos de Analytics en nuestra plataforma AWS, siendo su fuerte la integración de datos en todo su espectro y la generación de modelos analíticos predictivos y de Machine Learning. Como Select Partner de AWS, Datalytics nos apoya en la generación de valor a nuestras áreas de negocio, explorando continuamente nuevas alternativas de soluciones para los retos que se presentan“, Carlos Andrés Patiño, Director Servicios de Apoyo al Negocio, Nequi.


